Distributed Data Parallel (DDP)
Rough notes
When using DDP it is important to set the seed explicitly, since each process will initialize its own version of the model.
Sketch of PyTorch Lightning DDP:
num_nodes = 8
gpus_per_node = 8
world_size = num_nodes * gpus_per_node
# start training on each process
for node in num_nodes:
for gpu in gpus_per_node:
init_new_process()
set_environment_variables(world_size=world_size, group_rank=node, local_rank=gpu)
run_script('python train.py --arg1 val1 ...')
Basic example
Modified example from here: https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
Note:
- When using 'spawn' method, make sure call is run within
if __name__ == '__main__'block - Couldn't get this to work in jupyter notebook
- Span up an Azure ML NV12 series (2 x NVIDIA Tesla M60)
import os
import sys
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def setup(rank, world_size):
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
# initialize the process group
dist.init_process_group(
"nccl",
init_method='env://',
rank=rank,
world_size=world_size,
)
def cleanup():
dist.destroy_process_group()
def distribted_run(rank, world_size):
print(f"Running on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
model = ToyModel().to(rank)
ddp_model = DDP(
model,
device_ids=[rank],
output_device=rank,
)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(
ddp_model.parameters(),
lr=0.001,
)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 5).to(rank)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
print(f'Loss on rank {rank}: {loss}')
cleanup()
if __name__ == '__main__':
# nb. it is important to run this within if __name__ == '__main__' block
# since using 'spawn'
world_size = 2
# The function is called as ``fn(i, *args)``, where ``i`` is
# the process index and ``args`` is the passed through tuple
# of arguments.
mp.spawn(
fn=distribted_run,
args=(world_size,), # rank is passed as first arg
nprocs=world_size,
join=True, # Perform a blocking join on all processes.
)
Output:
Running on rank 0.
Running on rank 1.
Loss on rank 0: 1.3665930032730103
Loss on rank 1: 1.1837959289550781
Examples: Collective operations
A picture tells a thousand words: 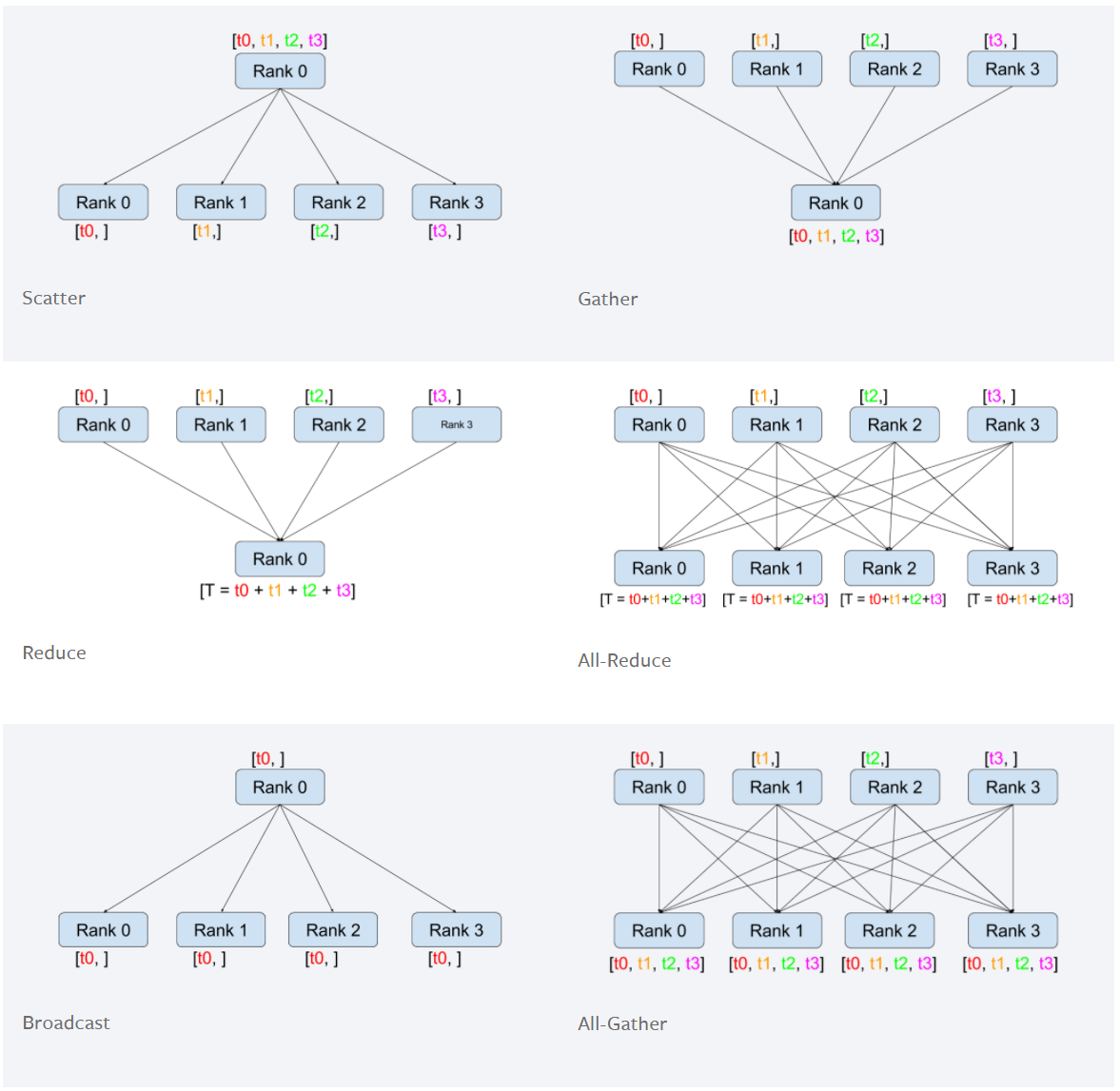
all_gather
def distribted_run(rank, world_size):
print(f"Running on rank {rank}.")
setup(rank, world_size)
x = torch.randn(1, 3).to(rank)
print(f"On rank {rank}:", x)
gathered_xs = [torch.zeros_like(x) for _ in range(world_size)]
dist.all_gather(tensor_list=gathered_xs, tensor=x)
print(f"Gathered on rank {rank}:", gathered_xs)
cleanup()
Output
Running on rank 1.
Running on rank 0.
On rank 1: tensor([[-1.4494, 0.5864, -1.4546]], device='cuda:1')
On rank 0: tensor([[-0.1952, -0.7890, 0.7067]], device='cuda:0')
Gathered on rank 0: [tensor([[-0.1952, -0.7890, 0.7067]], device='cuda:0'), tensor([[-1.4494, 0.5864, -1.4546]], device='cuda:0')]
Gathered on rank 1: [tensor([[-0.1952, -0.7890, 0.7067]], device='cuda:1'), tensor([[-1.4494, 0.5864, -1.4546]], device='cuda:1')]
gather
Note Gather is not supported with NCCL backend in my testing.
def distribted_run(rank, world_size):
# setup distributed backend
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
# initialize the process group
dist.init_process_group(
"gloo",
init_method='env://',
rank=rank,
world_size=world_size,
)
print(f"Running on rank {rank}.")
x = torch.randn(1, 3).to(rank)
print(f"On rank {rank}:", x)
# set destination rank
dst = 0
# define gather_list
# note: needs to be None on non-dst ranks
# note: should have "correct shape" on dst rank
gather_list = [torch.zeros_like(x) for _ in range(world_size)] if rank == dst else None
dist.gather(tensor=x, dst=dst, gather_list=gather_list)
print(f"Gather list on rank {rank}", gather_list)
cleanup()
Output
Running on rank 0.
Running on rank 1.
On rank 0: tensor([[-1.2718, -0.1054, -0.3968]], device='cuda:0')
On rank 1: tensor([[-0.3084, 1.3772, -0.4334]], device='cuda:1')
Gather list on rank 1 None
Gather list on rank 0 [tensor([[-1.2718, -0.1054, -0.3968]], device='cuda:0'), tensor([[-0.3084, 1.3772, -0.4334]], device='cuda:0')]
All Gather a list of tensors
all_gather operates on tensors. It can be inefficient to iterate over a list of tensors
one at a time and apply all_reduce. Instead we can:
torch.catthe list of tensors into a single tensortorch.distributed.all_reduceon this concatenated list of tensors, now a tensortorch.chunkis inverse to torch.cat
def distribted_run(rank, world_size):
setup(rank, world_size)
def dprint(string, obj):
'''Helper method to print on one rank at a time.'''
for i in range(world_size):
if rank == i:
print(f'Rank {rank}: {string}')
print(obj)
print()
dist.barrier()
print(f"Running on rank {rank}.\n")
list_of_tensors = [torch.randn(1, 2).to(rank) for _ in range(3)]
n = len(list_of_tensors)
dprint("List of tensors", list_of_tensors)
cat_list_of_tensors = torch.cat(list_of_tensors, -1)
dprint('Concatenated tensor', cat_list_of_tensors)
gathered_cat = [torch.zeros_like(cat_list_of_tensors) for _ in range(world_size)]
dist.all_gather(tensor_list=gathered_cat, tensor=cat_list_of_tensors)
dprint("Gathered concatenated", gathered_cat)
chunk_gathered_cat = []
for cat_list_of_tensors in gathered_cat:
chunk_cat = torch.chunk(cat_list_of_tensors, n, 1)
for t in chunk_cat:
chunk_gathered_cat.append(t)
dprint('Gathered un-concatenated', chunk_gathered_cat)
cleanup()
Output:
Running on rank 0.
Running on rank 1.
Rank 0: List of tensors
[tensor([[-0.3920, -0.2459]], device='cuda:0'), tensor([[0.3852, 0.7020]], device='cuda:0'), tensor([[2.5578, 1.0345]], device='cuda:0')]
Rank 1: List of tensors
[tensor([[-0.6233, -0.2735]], device='cuda:1'), tensor([[ 1.0148, -0.4607]], device='cuda:1'), tensor([[1.1005, 0.0173]], device='cuda:1')]
Rank 0: Concatenated tensor
tensor([[-0.3920, -0.2459, 0.3852, 0.7020, 2.5578, 1.0345]],
device='cuda:0')
Rank 1: Concatenated tensor
tensor([[-0.6233, -0.2735, 1.0148, -0.4607, 1.1005, 0.0173]],
device='cuda:1')
Rank 0: Gathered concatenated
[tensor([[-0.3920, -0.2459, 0.3852, 0.7020, 2.5578, 1.0345]],
device='cuda:0'), tensor([[-0.6233, -0.2735, 1.0148, -0.4607, 1.1005, 0.0173]],
device='cuda:0')]
Rank 1: Gathered concatenated
[tensor([[-0.3920, -0.2459, 0.3852, 0.7020, 2.5578, 1.0345]],
device='cuda:1'), tensor([[-0.6233, -0.2735, 1.0148, -0.4607, 1.1005, 0.0173]],
device='cuda:1')]
Rank 0: Gathered un-concatenated
[tensor([[-0.3920, -0.2459]], device='cuda:0'), tensor([[0.3852, 0.7020]], device='cuda:0'), tensor([[2.5578, 1.0345]], device='cuda:0'), tensor([[-0.6233, -0.2735]], device='cuda:0'), tensor([[ 1.0148, -0.4607]], device='cuda:0'), tensor([[1.1005, 0.0173]], device='cuda:0')]
Rank 1: Gathered un-concatenated
[tensor([[-0.3920, -0.2459]], device='cuda:1'), tensor([[0.3852, 0.7020]], device='cuda:1'), tensor([[2.5578, 1.0345]], device='cuda:1'), tensor([[-0.6233, -0.2735]], device='cuda:1'), tensor([[ 1.0148, -0.4607]], device='cuda:1'), tensor([[1.1005, 0.0173]], device='cuda:1')]